
Rodolfo M. Raya (rmraya@maxprograms.com)
Chief Technical Officer, Maxprograms
First published by IBM developerWorks, Aug 2004
Rodolfo M. Raya (rmraya@maxprograms.com)
Chief Technical Officer, Maxprograms
First published by IBM developerWorks, Aug 2004
Learn how XML standards help facilitate translation processes that involve many participants in different locations. This article focuses on the most common XML formats used in the localization industry to show you how important XML is becoming in multilingual document exchange.
Any company that seeks to operate in foreign markets knows that language technology is crucial to success. Contracts, product manuals, brochures, advertising campaigns, and everything else related to corporate communications must be fashioned and adapted to suit each different culture where commercial operations are to be carried out.
This article is an introduction to the use of XML in localization. Its objective is to provide the basis for future articles that will explain the technical aspects of the relevant XML standards.
A localization project comprises several steps and involves many participants.
Figure 1 illustrates a traditional process in five stages. (Blue boxes in the graphic represent processes that take place in house; yellow boxes show tasks done by the translation agency.)

The first stage is the creation of the documents that will need translation. For example, a typical software product might contain:
Other types of products, such as electrical appliances or automobiles, may not have RC files, but may instead require additional translation of things like complex Web sites, slide shows, or scripts for advertisements.
Once documentation is ready, it is sent to a translation agency or several independent translators. This stage is identified in Figure 1 as "Translation provider".
Usually, you need to translate more than one document format. This can be problematic for two reasons:
If you want to reduce costs, your first priority is to reduce the number of document formats.
Here's an alternative course of action:
By using this alternative method, a company can retain greater control over the process and its component parts. Additionally, the use of good computer aided translation (CAT) tools for text extraction can help reduce the need for post-translation DTP.
Figure 2 summarizes the steps described above.

The second stage ("Translation preparation") consists of converting strings into a special XML vocabulary and reusing existing translations if they are available. This is done using CAT tools or custom-made text filters.
Once the translation agency returns a translated XML document, all strings are reinserted in the original document. This process is known as reverse conversion and is performed using the same tools used in Step 1.
The procedures described above are not new. Many software companies experience problems that result from multiple document formats, and they are searching for an XML-based solution.
In 2001, several IT companies -- including Novell, Oracle, Sun, and IBM -- formed a technical committee to write the specification for XML Localisation Interchange File Format (XLIFF), which was formally published by the Organization for the Advancement of Structured Information Standards (OASIS) in 2002.
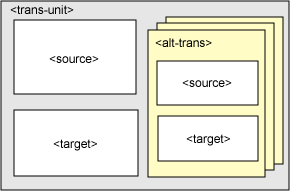
One of the advantages of XLIFF is its relative simplicity. An XLIFF file can be described as
a collection of translation units. Each translation unit contains a sentence or
paragraph that's extracted from the original document in an element called
<source>, and the translator has to fill a <target>
element
with the appropriate translation.
Legacy translations from previous projects can be added to a new translation unit using
<alt-trans> elements. Translators can use these translations as a guideline.
Sometimes the translation in an <alt-trans> element is perfect, and all the
translator has to do is accept the suggested text.
Figure 3 shows the relationship between the different components of a translation unit.
Listing 1 is an actual translation unit:
<trans-unit approved="no" id="1" resname="res1" xml:space="preserve">
<source xml:lang="en">Corporate Headquarters</source>
<target xml:lang="es">Casa Central de la Compañía</target>
<alt-trans match-quality="100" origin="web" tool="TM Search">
<source xml:lang="en">Corporate Headquarters</source>
<target xml:lang="es">Casa Central de la Compañía</target>
</alt-trans>
<alt-trans match-quality="92" origin="web" tool="TM Search">
<source xml:lang="en">"Corporate Headquarters"</source>
<target xml:lang="es">"Casa Central de la Compañía"</target>
</alt-trans>
</trans-unit>
Listing 1. Translation unit
Figure 4 shows a real implementation of an XLIFF editor with source text, target text, and proposed translations.
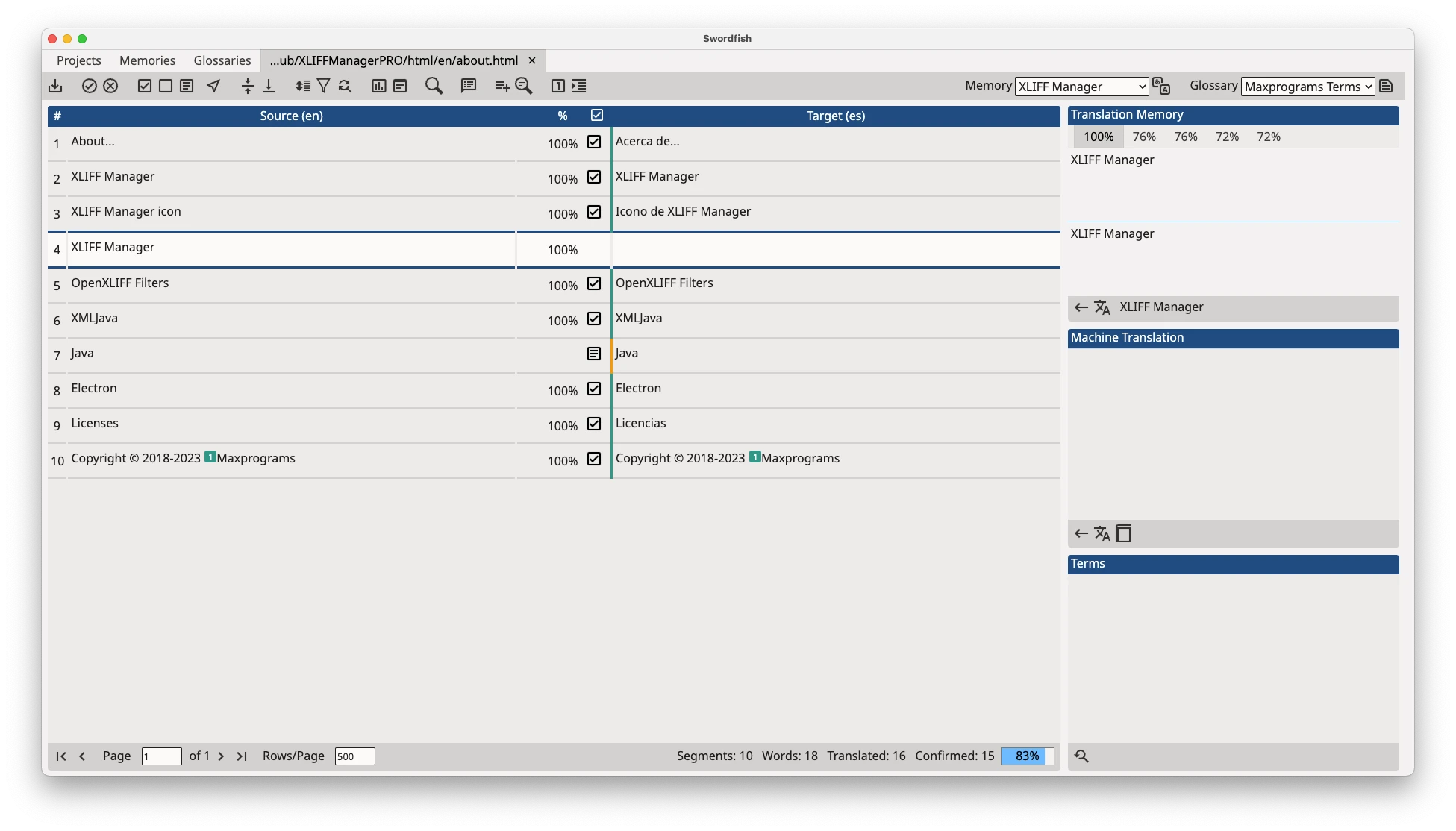
For more detailed information about this format, see the link to the XLIFF specification in Resources.
Possible translations contained in the <alt-trans> elements of an XLIFF file
are extracted from a translation memory (TM) database. Translation memory is a
language technology that enables the translation of segments (sentences, paragraphs, or
phrases) of documents by searching for similar segments in a database and suggesting matches
that are found in the database. For example, a TM can be built storing translated
<source>/<target> pairs from an XLIFF file in a relational
database or a specially designed TM server.
Technical manuals, legal contracts, and corporate Web sites usually contain text that is repeated in every published version. Therefore, it's a good idea to keep a TM database and reuse its content as much as possible. A good TM system can help achieve significant cost reductions in a localization project.
The Open Standards for Container/Content Allowing Re-use (OSCAR) group defined TMX as a common standard to allow users to reuse text more effectively when working with different CAT tools or translation providers.
From the TMX Web site:
TMX (Translation Memory eXchange) is the vendor-neutral open XML standard for the exchange of Translation Memory (TM) data created by Computer Aided Translation (CAT) and localization tools. The purpose of TMX is to allow easier exchange of translation memory data between tools and/or translation vendors with little or no loss of critical data during the process.
Both specifications, XLIFF and TMX, contain all the elements necessary to store source document formatting information in XML format. A good CAT tool will allow a translator to reuse a sentence from an HTML page when translating a Rich Text Format (RTF) document, keeping text layout intact. This is the key reason why TMX format should be used as a complement to XLIFF.
Like an XLIFF file, a TMX file is a collection of translation units. Each unit is represented
by a <tu> element and contains at least two translation unit
variants, or <tuv> elements. Each <tuv> element
specifies text in a given language. Listing 2 shows one of the
candidate translations used in Listing 1.
<tu tuid="1090682451312" creationdate="20040313T224601Z">
<tuv xml:lang="en">
<seg>Corporate Headquarters</seg>
</tuv>
<tuv xml:lang="es">
<seg>Casa Central de la Compañía</seg>
</tuv>
</tu>
Listing 2. Candidate translation used in Listing 1
The accompanying .zip file contains complete XLIFF and TMX examples (see Resources).
As XLIFF and TMX are both XML vocabularies, it is possible to use an XSL transformation to convert an XLIFF file to TMX format. (See Resources for a link to the Okapi Framework, a collection of XSL tools designed to enhance manipulation of translation-related XML materials.)
Translation memories are valuable assets. After a localization project is completed, all translations should be incorporated into the memories maintained by the company. By doing this, the company will increase the percentage of reused text with each project.
A glossary is a collection of specialized terms with their meanings and, optionally, their translations.
Contracts and technical manuals normally contain terms with specific meanings that pertain to a particular context. When a document is sent to a translator, it is usually accompanied by a glossary and, if preferred translations are included in the glossary, translators are expected to use the provided preferred translations.
A glossary can be written in any format. A spreadsheet with two columns could be enough to list terms and their translations. However, if the company is focused on terminological consistency, a simple list will not be enough.
To reiterate, the meaning of some terms is circumscribed in the given context. An entry in a glossary should have an explanation for each possible context, the preferred translation for each language of interest, and any additional attributes required by the people in charge of documentation. Without a good glossary, translators can turn a complex technical manual into a worthless document.
If a glossary is made available to a translator or translation agency, it should be in a useful format. The group that wrote the TMX standard (OSCAR) also wrote the specifications for TermBase eXchange (TBX), an XML-based common format that is almost universally accepted as the standard.
A TermBase, or terminological database, is a special kind of glossary in which terms are classified in several categories through user-defined attributes. TBX is one possible representation in XML format of the content of a terminological database.
In technical terms, TBX is a terminology markup framework (TMF), a markup language that complies with the ISO 12200 standard known as MARTIF.
TBX, like TMX and XLIFF, provides portability between different terminology tools and allows certain independence from tools vendors.
When translating regular prose, the length of the translation is seldom important. For example, German sentences are usually longer than their English counterparts, and it doesn't matter if a short story is one or two pages longer in German than in English.
The most widely used programming languages are C and C++. In C/C++, GUI text is commonly stored in resource files, plain text files that facilitate text extraction for translation. However, the author (or a visual tool) defines sizes for dialogue windows according to the size of the text in the original language. If after translation the length of the text changes, the layout will be affected. If the translation of a label is longer than the original, the text may be truncated; if it is shorter, the dialogue may end with undesired empty spaces.
Fortunately, the XLIFF standard includes attributes for specifying string position in a dialogue, font type and size used for the text, and many other details. A tool specifically designed for software localization can be used to visually adjust the dialogue layout during translation.
Java technology is the most widely used language after C/C++, and it is designed to facilitate software internationalization. Java applications that are ready for localization store GUI text in resource bundles, plain text files that, like their C/C++ counterparts, make text extraction a simple task. However, Java technology has an advantage over C/C++: GUI objects can be dynamically adjusted at execution time according to the length of the text that the object contains. This feature makes the Java language one of the better choices for developing multilingual applications.
Localization and all aspects of globalization depend heavily on technology. This introductory article has briefly presented the most relevant XML standards used in the localization industry -- XLIFF, TMX, and TBX -- and given hints on their usage. XML technology is not new, but its imaginative application in translation-related tasks is growing steadily, transcending corporative environments and reaching small companies looking to succeed in the global marketplace.
The next article in this series will explore the details of conversion to XLIFF and back using Java technology for common file formats, like plain text or HTML. I'll include a complete conversion tool for Java resource bundles.

Rodolfo M. Raya is involved in the development of localization standards including XLIFF, TMX, TBX, SRX, and GlossML.
He develops tools and libraries that implement these specifications, including the software and validation services available on this site.